爬取steam数据,近年来Steam游戏平台的用户数量不断增加,游戏种类也愈加丰富,这为研究Steam游戏市场提供了丰富的数据资源。而针对Steam游戏数据的分析,Python已经成为了一种非常流行的工具。在本篇文章中我们将学习如何使用Python爬取Steam游戏数据,并通过数据分析来了解Steam游戏市场的趋势和一些有价值的信息。无论是想要进行游戏开发还是投资游戏市场,这些数据和分析都将有着重要的意义。
Steam游戏数据分析教程python实现
分为两大部分
一.爬取steam游戏信息:需要有相关包‘requests’,‘bs4’,‘pandas’,‘re’
二.清洗数据及数据可视化:需要有相关包‘pandas’,‘re’,matplotlib’,‘pandas’,‘numpy’
一.爬取steam游戏信息整体来说steam还是很好爬的,不加headers都可以成功get到页面,但是因为有的游戏页面进入前会验证年龄之类的,解决方法:重新抓重新定向的页面。我嫌麻烦,直接在账号设置里可以关闭提示,然后加headers就没有这个问题了。而且不需要代理池和限制频率,还是很友好的。
1.1 先爬热销游戏的列表
主要就提取游戏的链接和ID,转成dataframe然后保存。steam每个游戏都有自己的ID,比如csgo的链接是store.steampowered.com/app/730/CounterStrike_Global_Offensive/
730就是游戏的ID,后面就是游戏的名字,即使不加名字也是可以重定向到这个页面。本来是想通过链接提取游戏名字的,结果发现汉字名字在链接中不会显示,比如三国志14:
https://store.steampowered.com/app/872410/14/
的只会显示14,索性放弃,在后面1.2中再提取游戏名字。另外get的网址后面已经加上过滤DLC的参数了。
如果你是Python初学者:一共需要修改3个参数 一个是headers,一个是爬取页数n的值,以及保存路径path,然后run就可以了。
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
headers = {
'Accept': '',
'Accept-Encoding': '',
'Accept-Language': '',
'Cache-Control': '',
'Connection': '',
'Cookie':'',
'Host': '',
'Sec-Fetch-Mode': '',
'Sec-Fetch-Site': '',
'Sec-Fetch-User': '',
'Upgrade-Insecure-Requests': '',
'User-Agent': ''
}
#替换你自己的headers
n = 20
#n代表爬取到多少页
path = '1.xlsx'
#修改你的保存位置
def getgamelist(n):
linklist=[]
IDlist = []
for pagenum in range(1,n):
r = requests.get('https://store.steampowered.com/search/?ignore_preferences=1&category1=998&os=win&filter=globaltopsellers&page=%d'%pagenum,headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
soups= soup.find_all(href=re.compile(r"https://store.steampowered.com/app/"),class_="search_result_row ds_collapse_flag")
for i in soups:
i = i.attrs
i = i['href']
link = re.search('https://store.steampowered.com/app/(\d*?)/',i).group()
ID = re.search('https://store.steampowered.com/app/(\d*?)/(.*?)/', i).group(1)
linklist.append(link)
IDlist.append(ID)
print('已完成'+str(pagenum)+'页,目前共'+str(len(linklist)))
return linklist,IDlist
def getdf(n):#转df
linklist,IDlist = getgamelist(n)
df = pd.DataFrame(list(zip(linklist,IDlist)),
columns =['Link', 'ID'])
return df
if __name__ == "__main__":
df = getdf(n)#n代表爬取到多少页
df.to_excel(path)#储存df是这个样子的:

1.2爬详细信息。基本思路是对df遍历每行数据。对于每行来说,用requests.get(Link),再用bs4解析,然后提取出关键字(名字,价格,好评率,评论等),然后写入df中。
def gamename(soup): #游戏名字
try:
a = soup.find(class_="apphub_AppName")
k = str(a.string)
except:
a = soup.find(class_="apphub_AppName")
k = str(a.text)
return k
def gameprice(soup):#价格
try:
a = soup.findAll(class_="discount_original_price")
for i in a:
if re.search('¥|free|免费', str(i),re.IGNORECASE):
a = i
k = str(a.string).replace(' ', '').replace('\n', '').replace('\r', '').replace(' ', '')
except:
a = soup.findAll(class_="game_purchase_price price")
for i in a:
if re.search('¥|free|免费', str(i),re.IGNORECASE):
a = i
k = str(a.string).replace(' ', '').replace('\n', '').replace('\r', '').replace(' ', '')
return k
def taglist(soup):#标签列表
list1=[]
a = soup.find_all(class_="app_tag")
for i in a:
k = str(i.string).replace(' ', '').replace('\n', '').replace('\r', '')
if k == '+':
pass
else:
list1.append(k)
list1 = str('\n'.join(list1))
return list1
def description(soup): #游戏描述
a = soup.find(class_="game_description_snippet")
k = str(a.string).replace(' ', '').replace('\n', '').replace('\r', '')
return k
def reviewsummary(soup): #总体评价
a = soup.find(class_="summary column")
try:
k = str(a.span.string)
except:
k=str(a.text)
return k
def getdate(soup): #发行日期
a = soup.find(class_="date")
k = str(a.string)
return k
def userreviewsrate(soup):#总体数量好评率
a = soup.find(class_="user_reviews_summary_row")
k = str((a.attrs)['data-tooltip-html'])
return k
def developer(soup): #开发商
a = soup.find(id="developers_list")
k = str(a.a.string)
return k
def getreviews(ID):#获取评论
r1 = requests.get(
'https://store.steampowered.com/appreviews/%s?cursor=*&day_range=30&start_date=-1&end_date=-1&date_range_type=all&filter=summary&language=schinese&l=schinese&review_type=all&purchase_type=all&playtime_filter_min=0&playtime_filter_max=0&filter_offtopic_activity=1'%str(ID),headers=headers.timeout=10)
soup = BeautifulSoup(r1.json()['html'], 'lxml')
a = soup.findAll(class_="content")
list1 = []
for i in a:
list1.append(i.text.replace(' ', '').replace('\n', '').replace('\r', '').replace(' ', ','))
k=str('\n'.join(list1))
return k
def getdetail(x):
tag, des, reviews, date, rate, dev, review,name,price = ' ', ' ', ' ', ' ', ' ', ' ', ' ',' ',' '
global count
try:
r = requests.get(x['Link'], headers=headers.timeout=10)
except:
print('服务器无响应1')
try:
r = requests.get(x['Link'], headers=headers.timeout=10)
except:
print('服务器无响应2')
try:
r = requests.get(x['Link'], headers=headers.timeout=10)
except:
print('服务器无响应3')
try:
soup = BeautifulSoup(r.text, 'lxml')
name = gamename(soup)
tag = taglist(soup)
des = description(soup)
reviews = reviewsummary(soup)
date = getdate(soup)
rate = userreviewsrate(soup)
dev = developer(soup)
review = getreviews(str(x['ID']))
price = gameprice(soup)
print('已完成: '+name+str(x['ID'])+'第%d个'%count)
except:
print('未完成: '+str(x['ID'])+'第%d个'%count)
price = 'error'
count += 1
return name,price,tag,des,reviews,date,rate,dev,review
if __name__ == "__main__":
df1 = pd.read_excel('1.xlsx')
count = 1
df1['详细'] = df1.apply(lambda x: getdetail(x), axis=1)
df1['名字'] = df1.apply(lambda x: x['详细'][0], axis=1)
df1['价格'] = df1.apply(lambda x: x['详细'][1], axis=1)
df1['标签'] = df1.apply(lambda x: x['详细'][2], axis=1)
df1['描述'] = df1.apply(lambda x: x['详细'][3], axis=1)
df1['近期评价'] = df1.apply(lambda x: x['详细'][4], axis=1)
df1['发行日期'] = df1.apply(lambda x: x['详细'][5], axis=1)
df1['近期数量好评率'] = df1.apply(lambda x: x['详细'][6], axis=1)
df1['开发商'] = df1.apply(lambda x: x['详细'][7], axis=1)
df1['评论'] = df1.apply(lambda x: x['详细'][8], axis=1)
df1.to_excel('2.xlsx')
print('已完成全部')大概说几句,各个函数中实在懒得给变量起名字了。评价指标选择的是近期,不是总体。因为我没想到能够用apply函数同时,在dataframe中写入多列的方法。所以发送一次get请求后把各类信息作为元组打包写入['详细'],最终还要把['详细']里的元组再依次提取出来写入各列。结果如下图,

我一共爬了一万个游戏,不同时期获取的结果也会有所不同,因为地区限制等原因某些游戏不在国区卖,所以是直接df中drop还是自备梯子就取决于你自己了。
1.3爬在线人数steam自己有个数据统计的网页,直接while循环+time.sleep简单粗暴,每10分钟以当前时间为名把数据直接保存为xlsx格式。我直接丢vps上24小时跑了。
while True:
try:
r = requests.get('https://store.steampowered.com/stats/Steam-Game-and-Player-Statistics?l=schinese',headers = headers ,timeout=15)
if r.status_code == 200:
soup = BeautifulSoup(r.text, 'lxml')
a = soup.findAll(class_="player_count_row")
NOW =[]
MAX=[]
ID=[]
for i in a :
NOW.append(str(i.contents[1].span.string))
MAX.append(str(i.contents[3].span.string))
ID.append(re.search('\d+',str(i.contents[7].a.attrs['href'])).group())
df = pd.DataFrame(list(zip(NOW, MAX,ID)),
columns =['now','max', 'ID'])
df1 = df.set_index('ID')
path_stats = str(time.strftime("%Y年%m月%d日%H时%M分%S秒",time.localtime()))+'.xlsx'
df1.to_excel(path_stats)
print(path_stats)
time.sleep(600)
except:
pass二.清洗数据及数据可视化:2.1数据清洗这部分相对简单,因为爬取的数据已经相对来说比较规范了。由于我忘记备份最初始的原始文档了,所以以下范例只用200条游戏数据做的。
首先
import pandas as pd import re
然后读取之前爬虫的结果
path = '' df = pd.read_excel(path,index_col=0) df.info()#看一下数据结构
结果如下
首先看一下价格这一列

实际在爬虫爬取的游戏中,大多数都是价格。少部分是‘免费游玩’‘Free’之类的,极少部分是游戏demo,游戏demo这个就很烦,还要根据实际情况判断游戏价格,由于数量极少,直接归为免费游戏。
def price(x):
try:
pricenum = int(x['价格'].replace('¥',''))
except:
pricenum = 0
return pricenum
df['价格'] = df.apply(lambda x:price(x),axis=1)
df['价格'] = pd.to_numeric(df['价格'])#转为int64
df.info()结果如下,可以看到价格一列已经变成int64
接下来提取评价人数和好评率
def getreviewsnum(x):
x1 = x['总体数量好评率']
x2 = x['总体评价']
if re.search('过去 30 天内的 (.*?) 篇用户评测中有 (\d*%) 为好评。',x1):
num = re.search('过去 30 天内的 (.*?) 篇用户评测中有 (\d*%) 为好评。',x1).group(1)
elif re.search('(\d*) 篇用户的游戏评测中有 (\d*%) 为好评。',x1):
num = re.search('(\d*) 篇用户的游戏评测中有 (\d*%) 为好评。',x1).group(1)
elif re.search('\d* 篇用户评测',x2):
num = re.search('(\d*) 篇用户评测',x2).group(1)
else:
num = '0'
return num
def getreviewsrate(x):
x = x['总体数量好评率']
if re.search('过去 30 天内的 (.*?) 篇用户评测中有 (\d*%) 为好评。',x):
rate = re.search('过去 30 天内的 (.*?) 篇用户评测中有 (\d*%) 为好评。',x).group(2)
elif re.search('(\d*) 篇用户的游戏评测中有 (\d*%) 为好评。',x):
rate = re.search('(\d*) 篇用户的游戏评测中有 (\d*%) 为好评。',x).group(2)
else :
rate=''
return rate
df['评价数量']=df.apply(lambda x:getreviewsnum(x),axis=1)
df['好评率']=df.apply(lambda x:getreviewsrate(x),axis=1)
df结果如下,可以看到后面多了2列

然后同价格一样,转一下格式
df['评价数量'] = df['评价数量'].apply(lambda x:x.replace(',',''))
df['好评率'] = df['好评率'].apply(lambda x:str(x).replace('%',''))
df['评价数量'] = pd.to_numeric(df['评价数量'])
df['好评率'] = pd.to_numeric(df['好评率'])
df['ID'] = df['ID'].astype('str')#这里顺路把ID转为str
df.to_excel(path)最后说一下发行时间这里,这里又有一些坑,因为存在部分数据没有日或者月的情况,所以我并没找到简便的方式把日期变成datetime格式。这里如果有大佬可以教我一下,不胜感激。
但是方法总是有的嘛,打开excel,把这一列改为短日期格式,但是并没有变化。这里如果双击一下那个单元格,发现变成了我们想要的格式,
怎么批量改呢,我在网上搜到这样的方式
数据→分列→下一步→下一步(选择日期)→完成
然后就ok了,5秒搞定。
这时我们重新读一下df发现已经变成datetime64格式了。

把爬取过程中产生的没用的列删掉,最后保存
df=df.drop('Unnamed: 0.1', axis=1)
df.to_excel(path)关于游戏玩家实时数量的数据我打算攒够一个月再做清洗分析,等数据量够了我再补这部分的内容。
2.2 数据可视化
首先
#coding:utf-8 import pandas as pd import numpy as np import matplotlib.pyplot as plt from matplotlib import cm import datetime plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
读取文件,把发行日期的年份提取到额外的一列['year']后面会用到,然后选取前一千行制作一份copy,选取评价数量为0的也就是未发售的游戏也制作一份copy。
dfraw = pd.read_excel(path,index_col=0) dfraw['year'] = dfraw.apply(lambda x:str(x['发行日期'])[0:4],axis = 1) df = dfraw.copy() df_top1k = dfraw[0:1000].copy() df_now = dfraw[dfraw['评价数量'].values!=0].copy()
看一下整体情况,这里我爬了一万条,但是有些未在国区发售,去除掉之后还剩9887条。
df.info() df.describe()

可以看到平均游戏价格41.91,平均好评率79.28,画出一个散点图看一下分布情况
Y = df_now['价格'] # 每一个点的Y值
X = df_now['发行日期']# 每一个点的X值
plt.style.use('seaborn')#画布风格
plt.rcParams['font.sans-serif']=['Microsoft YaHei']#字体
plt.figure(figsize=(20, 5))#大小
#这里散点大小是热销排行的倒数,也就是说越热销的游戏,圆点也就越大
#颜色取决于好评率高低,colorbar也就是cmap选择'RdYlBu'风格
plt.scatter(X,Y, s=15000/(df_now.index+200), c=df_now['好评率'], alpha=.9,cmap=plt.get_cmap('RdYlBu'))
plt.colorbar().set_label('好评率',fontsize=20)
plt.xlabel('年份',fontsize=20)
plt.ylabel('价格',fontsize=20)
plt.show()
可以看到已发布的游戏绝大多数分布在2010年到2020年,0到200元以内,少部分游戏突破了400元。如果局部放大一下
Y = df_now['价格'] # 每一个点的Y值
X = df_now['发行日期']# 每一个点的X值
plt.style.use('seaborn')#画布风格
plt.rcParams['font.sans-serif']=['Microsoft YaHei']#字体
plt.figure(figsize=(20, 5))#大小
#这里散点大小是热销排行的倒数,也就是说越热销的游戏,圆点也就越大
#颜色取决于好评率高低,colorbar也就是cmap选择'RdYlBu'风格
plt.scatter(X,Y, s=15000/(df_now.index+200), c=df_now['好评率'], alpha=.9,cmap=plt.get_cmap('RdYlBu'))
datenow = datetime.datetime(2021,1,1)
dstart = datetime.datetime(2010,1,1)
plt.xlim(dstart, datenow)
plt.ylim(0, 500)
plt.xlabel('年份',fontsize=20)
plt.ylabel('价格',fontsize=20)
plt.colorbar().set_label('好评率',fontsize=20)
plt.show()
接下来以年分组进行平均价格和平均好评率的计算绘入图中,
df_yearprice = df.groupby('year')['价格'].mean().to_frame().reset_index().sort_values(by='year')#按年分组,求平均价格
df_yearreview = df.groupby('year')['好评率'].mean().to_frame().reset_index().sort_values(by='year')#按年分组,求平均好评率
plt.figure(figsize=(20, 5))
plt.plot(df_yearreview['year'],df_yearreview['好评率'], c='g',label='平均好评率%')
plt.plot(df_yearprice['year'],df_yearprice['价格'], c='c',label='平均价格')
plt.xlabel('年份',fontsize=20)
plt.legend()
plt.title('年份与价格、好评率')
plt.xlim(4,35)
plt.ylim(0, 100)
plt.show()
从1990年到2020年游戏平均价格从20多增长到50多,相对比,2019年2个月猪肉就能翻一倍。但这样对比其实并不科学,因为可以看出来2019年以前在2013年平均价格达到了峰值,之后因为涌入了大量的免(ke)费(jin)游戏以及游戏模式的改变(比如开箱子GO、DLC DAY 2等)导致游戏的入门价格平均值在不断的被拉低。好评率在30年内还算相对稳定。
接下来根据游戏类型做一个整体统计,根据我们爬的游戏标签对游戏做分类,首先做标签的词频统计,这里的思路就是把所有的标签作为一个list,然后遍历list统计为dict,然后做降序处理。这里绘2次图选择不同的数据源,一次全部一万个游戏,一次为前1000个游戏。以下代码是全部一万个,前1000只需要把所有df改为df_top1k就可以。
list1 = []
list1 = df['标签'].to_list()#全部一万个
list1 = '\n'.join(list1)
list1 =list1.split('\n')#把所有标签加入list1
frequency = {}
frequency1 = {}
for word in list1:#词频统计
if word not in frequency:
frequency[word] = 1
else:
frequency[word] += 1
frequency = sorted(frequency.items(),key = lambda x :x[1], reverse=True)#根据词频降序做排列输出一个元组
for i in frequency:
frequency1[str(i[0])[0:2]+'\n'+str(i[0])[2:4]+'\n'+str(i[0])[4:6]+'\n'+str(i[0])[6:8]]=i[1]#元组转为字典,再让标签每隔2个字加\n,后面柱状图会用到
dffre = df.copy()
for i in list(frequency)[0:50]:#检验50个tag覆盖率
dffre = dffre[dffre['标签'].str.contains(i[0])== False]
print(len(dffre))
这里输出了21,说明50个游戏标签覆盖了绝大多数游戏,只有21个游戏没在这个范围内。然后绘图不再详细说了,跟前面差不多。
Y = list(frequency1.keys())[0:50]#取前50个标签
X = list(frequency1.values())[0:50]
plt.figure( figsize=(20, 5),)
plt.bar(Y,X, facecolor='#ff9999', edgecolor='white')
plt.xlabel('游戏类型',fontsize=20)
plt.ylabel('游戏数量',fontsize=20)
plt.xlim(-.5, 49.5)
for a,b in zip(Y,X):
plt.text(a, b,int(b), ha='center', va= 'bottom',fontsize=10)
plt.show()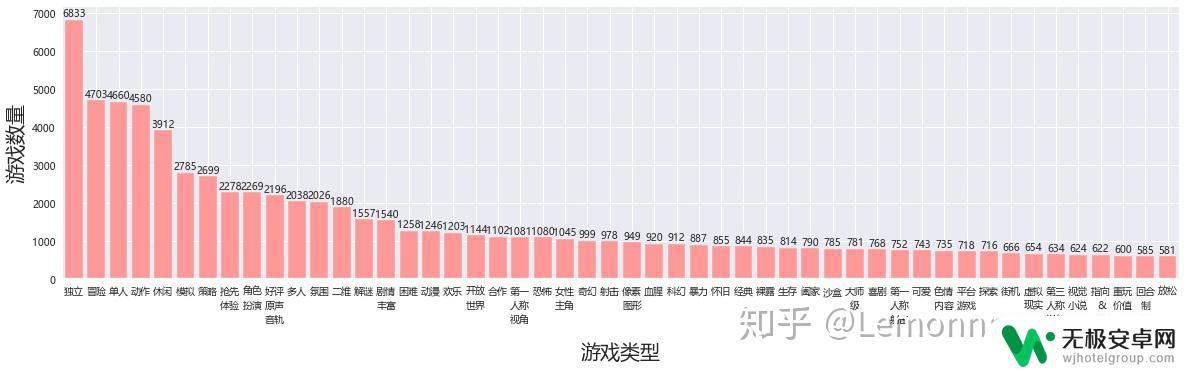 数据源为全部的结果
数据源为全部的结果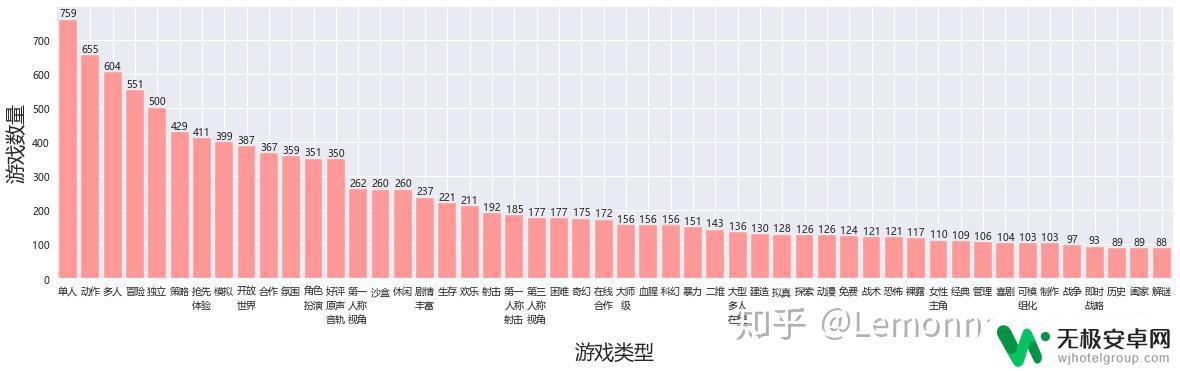 数据源为热销榜前一千的结果
数据源为热销榜前一千的结果从整体上讲,都符合长尾型分布,独立 单人 动作 冒险这四种无论是否为热销游戏,都是热门标签。令我最吃惊的居然是单机的标签数量占比居然这么高,热销榜11.7%的游戏居然有裸露标签。
今天先更到这,后面改天再更
通过爬取Steam游戏数据,我们可以更深入地探索不同游戏之间的差异,了解玩家游戏习惯和偏好,进而提高游戏研发和销售的效率。Python作为一种广泛使用的编程语言,可以很好地帮助我们实现这一目标。希望这篇教程能够帮助更多的数据分析爱好者和游戏从业人员,共同促进游戏行业的发展。









